This article is after the prior article, "Fast Edge Detection on 4xMSAA with Light pre-pass": http://wrice.blogspot.com/2010/03/fast-edge-detection-on-msaa-with-light.html
Today I found that I can run fragment shaders per sampling point on PS3. It wasn't quite obvious on the document so that I wasn't sure until I see the result. The way PS3 allows us to run at sampling point is to set "sample mask" on MSAA surface. By doing that, I can decide which sampling point I will store the result from the fragment shader. It is a bit mask style, so that the result can go to more than one sampling point.
On my prior article, I said "we need to calculate light value at sampling points and then we need to average the light values." Now we can fetch only one normal sampling point and one depth sampling point per sampling point; no need to average any. After this, I found the Light buffer became more like MSAA buffer.
There were several things to notice on the major change. Since we store the light values per sampling point, we don't need sum up or average it. Later, we can get the averaged value by using linear filter on the light buffer. I expect this can buy us some time.
A downside is that now we need to render the light geometry, or quad, three times more on the edges. Including non-edge lighting, we need to render the light geometry total five times; one for non-edge and four for each sampling point.
Although we need to run 4 times of the edge fragment shader, each fragment shader became lighter. Now it does only two times of texture fetching: one on the normal buffer and one on the depth buffer. It was eight times before: four on normal buffer and four on depth. Therefore the total cost seems almost same; in fact, I need to do the performance test more.
The next change was to use Centroid on the fragment shader that actually renders each object with materials. Without centroid, the last result may not have any difference. :-)
I was very happy. The result looked just perfect. I kept seeing dark pixels around edges even after I adopted the fast edge detection. Now the result is very very nice and even beautiful.
*PS : please leave any similar papers or articles so that I can improve this method.
Mar 27, 2010
Gaussian filter at run-time
Today I found that PlayStation3 has "3x3 Gaussian filter" as a texture filter. I was surprised, because Gaussian filter is known as an expensive filter. On second thought, I found that it is actually not too crazy expensive. 3x3 Gaussian filter is like this:
On second thought, I found that it is actually not too crazy expensive. 3x3 Gaussian filter is like this:
[ 1 2 1]
[ 2 4 2]
[1 2 1] / 16
To get the filtered result, we can actually do it by 4 times of texture fetching with bilinear filter, which most of graphic cards support.
(
[ 0.25 0.25 0 ]
[ 0.25 0.25 0 ]
[ 0 0 0 ]
+
[ 0 0.25 0.25 ]
[ 0 0.25 0.25 ]
[ 0 0 0 ]
+
[ 0 0 0 ]
[ 0.25 0.25 0 ]
[ 0.25 0.25 0 ]
+
[ 0 0 0 ]
[ 0 0.25 0.25 ]
[ 0 0.25 0.25 ] ) /4
I haven't thought that I can use Gaussian filter at run-time. I wonder why I haven't heard from anybody else or any books. Did I just forget with getting older? :-)
It can be useful on blur or glow effects. It can also help alias problems.
By doing the same trick double times, we can get 5x5 Gaussian result. 5x5 Gaussian filter requires 25 pixel colors for each result pixel. With the trick, it takes only 8 times of texture fetching rather than 25 times. If the PS3 hardware Gaussian filter is fast enough, it will cost only two times of texture fetching. Tomorrow I will try this idea and see how much it will cost. I'm guessing it will cost about 5ms... And I will also test the PS3 Hardware Gaussian filter too.
Tomorrow I will try this idea and see how much it will cost. I'm guessing it will cost about 5ms... And I will also test the PS3 Hardware Gaussian filter too.
 On second thought, I found that it is actually not too crazy expensive. 3x3 Gaussian filter is like this:
On second thought, I found that it is actually not too crazy expensive. 3x3 Gaussian filter is like this:[ 1 2 1]
[ 2 4 2]
[1 2 1] / 16
To get the filtered result, we can actually do it by 4 times of texture fetching with bilinear filter, which most of graphic cards support.
(
[ 0.25 0.25 0 ]
[ 0.25 0.25 0 ]
[ 0 0 0 ]
+
[ 0 0.25 0.25 ]
[ 0 0.25 0.25 ]
[ 0 0 0 ]
+
[ 0 0 0 ]
[ 0.25 0.25 0 ]
[ 0.25 0.25 0 ]
+
[ 0 0 0 ]
[ 0 0.25 0.25 ]
[ 0 0.25 0.25 ] ) /4
I haven't thought that I can use Gaussian filter at run-time. I wonder why I haven't heard from anybody else or any books. Did I just forget with getting older? :-)
It can be useful on blur or glow effects. It can also help alias problems.
By doing the same trick double times, we can get 5x5 Gaussian result. 5x5 Gaussian filter requires 25 pixel colors for each result pixel. With the trick, it takes only 8 times of texture fetching rather than 25 times. If the PS3 hardware Gaussian filter is fast enough, it will cost only two times of texture fetching.
 Tomorrow I will try this idea and see how much it will cost. I'm guessing it will cost about 5ms... And I will also test the PS3 Hardware Gaussian filter too.
Tomorrow I will try this idea and see how much it will cost. I'm guessing it will cost about 5ms... And I will also test the PS3 Hardware Gaussian filter too.
Mar 26, 2010
Fast edge detection on MSAA with Light Pre-Pass
I have spent a whole week for solving an aliasing problem on 4xMSAA and Light pre-pass technique. I think it is a time for me to write about my experience.
Light pre-pass consists of three steps: rendering normal/depth buffer, rendering lights and rendering objects with proper materials.
Light pre-pass is more friendly to MSAA than deferred shading, because on the last rendering phase objects can utilize MSAA. On the other hand, objects on deferred shading cannot get any benefits from MSAA while lights may get some. I believe this is why Wolfgang said "It works with MSAA definitely": http://diaryofagraphicsprogrammer.blogspot.com/2008/03/light-pre-pass-renderer.html
However, there are two problems: one is between the light buffer and the last accumulation buffer, and another problem is on between normal/depth buffer and the light buffer.
When we render lights on the light buffer, MSAA doesn't work. It means that even if we use 4xMSAA setting for the light buffer, the result values on the four colors of each pixel are all the same. It is because light geometries are usually a simple sphere or a small quad. Thus when we render objects as the last step, we cannot get light values at MSAA sampling level, because we don't have enough light information for each sampling point.
One possible way to solve this problem is to do the light rendering per MSAA sampling point. Executing the pixel shader per sampling point will allow us to store each light value per sampling point. Then the light value will be selected by centroid value. Since not every graphic cards allows to run at sampling point, storing the averaged light values is an alternative way.
Another problem is on between the normal/depth buffers and light buffer. Since we are rendering objects on the normal and depth buffers, MSAA properly works on the normal/depth buffers. Then when we render the light buffer, we need to fetch four sampling points from the normal buffer and four sampling points from the depth buffer. It is because we need to calculate light value at sampling points and then we need to average the light values. If we just use linear filter for normal buffer and take the average of the normal values on a pixel, the normal value will have no proper meaning. The depth value is also the same. For example if we have 4 depth values on a pixel: 0, 0, 1, and 1. Then the linearly averaged value will be 0.5, but there was no objects at the depth position.
Since the pixel shader needs to fetch 8 texels, it is very expensive. One way to solve this problem is to differentiate edge pixels from non-edge pixels. On non-edge pixel, we perform one time calculation, while we still do four times calculation on edge pixels.
To practically implement this idea, a cheap edge detection step is required. On Wolfgang's blog, a guy, benualdo, left an interesting idea: http://diaryofagraphicsprogrammer.blogspot.com/2010/03/edge-detection-trick.html
From his idea, I postulated an interesting characteristics of normal values. The length of a normal value is always one by the definition. However, if we linearly interpolate two normal values, the length may decrease. The length will be kept at one only when the normal values are the same. By this characteristics, we can determine whether a pixel includes four same normal values or not by checking the length of the averaged normal value. In other words, by one time of texture fetching with linear filter, we are able to check four normal values; we save three times of texture fetching. I will call this "normal length checking".
The bigger problem was on the depth checking part. I spent about 3 days thinking of depth checking with any similar way to the normal length checking trick. The first way I came up with is to make the 1 dimensional depth value to be 2 dimensional value; ( y = depth, x = 1 - depth ), and normalize it. When the depth values are different, linearly interpolating the normalized value will make the length smaller. This interesting idea didn't work, because we usually use 24 bits for depth and we need 24bits + 24bits to do this. Although I found that 24bits + 16bits is enough to detect edges, I could not accommodate the 2 bytes on any buffers. Normal buffer needs to use 3 channels for the normal and only one channel is left. I tried to encode the normal values onto 2 channels, but I found 2 channels are not enough to do the normal length checking trick. Thus I had to find another way.
My last choice was to use normal direction checking. The way is similar to the toon shading edge detection. When a normal value points to outward from the screen, the pixel is an edge pixel; edge = 0.2 > dot( normal, (0, 0, 1) ). A difference is that on our case false-positive is allowed. In other words, the result will be fine even if we misjudge a non-edge as an edge; we will need little bit more calculations but the result will be the same. On toon shading, this kind of false-positive will make the edge line thicker, which make the result bad.
To prevent too much performance leak, I adopted the Centroid trick that is well explained on ShaderX7. The assumption is that if a pixel is inside of a triangle, it is not an edge pixel, so that we can easily reject those non-edge pixels by checking the centroid value. This reduces a big amount of false-positive edges from the normal direction checking. The centroid information is stored on the alpha channel of the normal buffer.
I like to add some of comments about the centroid trick. The basic idea was very interesting. However, after I implemented it, I soon found that it gave me almost wire-frame-like edges. For example if we have a sphere which consists of several triangles, the centroid trick will indicate those seam parts between triangles as edges. But those pixels are not edges in the sense of normal continuity and depth continuity. In addition, if we use normal map during the normal buffer rendering, pixels in the middle of triangles may need to be considered as edges due to the normal discontinuity. Furthermore, PS3 is based on tiles. The wire-frame-like edges are actually covering almost every screen, although they are sparse. The Stencil cull implementation on PS3 was almost disabled in the situation.
PS3 had another problem with the Centroid trick. PS3 sends the identical value as a centroid value where a pixel is partially covered if the polygon covers the middle of the pixel. It was mentioned on the document and a DevNet supporting guy told me the behavior is hardware-wired so that they have no way to change it. According to my rough calculation only 2/3 of actual edges are detected by the Centroid trick. In other words 1/3 are missed. I couldn't give up this trick, because it makes the edge detection very fast, although the quality may decrease.
 On my implementation, first the normal length checking will return edges. Remain pixels are tested with the centroid trick, and then the normal direction checking takes place. This requires only 1 time of texture fetching and was fast enough to perform in 1.25ms at 720p.
On my implementation, first the normal length checking will return edges. Remain pixels are tested with the centroid trick, and then the normal direction checking takes place. This requires only 1 time of texture fetching and was fast enough to perform in 1.25ms at 720p.
The result between the normal direction checking and the depth checking on four texels, which is expensive, was little bit different, but the direction checking was very good enough with respect to the cost.
Light pre-pass consists of three steps: rendering normal/depth buffer, rendering lights and rendering objects with proper materials.
Light pre-pass is more friendly to MSAA than deferred shading, because on the last rendering phase objects can utilize MSAA. On the other hand, objects on deferred shading cannot get any benefits from MSAA while lights may get some. I believe this is why Wolfgang said "It works with MSAA definitely": http://diaryofagraphicsprogrammer.blogspot.com/2008/03/light-pre-pass-renderer.html
However, there are two problems: one is between the light buffer and the last accumulation buffer, and another problem is on between normal/depth buffer and the light buffer.
When we render lights on the light buffer, MSAA doesn't work. It means that even if we use 4xMSAA setting for the light buffer, the result values on the four colors of each pixel are all the same. It is because light geometries are usually a simple sphere or a small quad. Thus when we render objects as the last step, we cannot get light values at MSAA sampling level, because we don't have enough light information for each sampling point.
One possible way to solve this problem is to do the light rendering per MSAA sampling point. Executing the pixel shader per sampling point will allow us to store each light value per sampling point. Then the light value will be selected by centroid value. Since not every graphic cards allows to run at sampling point, storing the averaged light values is an alternative way.
Another problem is on between the normal/depth buffers and light buffer. Since we are rendering objects on the normal and depth buffers, MSAA properly works on the normal/depth buffers. Then when we render the light buffer, we need to fetch four sampling points from the normal buffer and four sampling points from the depth buffer. It is because we need to calculate light value at sampling points and then we need to average the light values. If we just use linear filter for normal buffer and take the average of the normal values on a pixel, the normal value will have no proper meaning. The depth value is also the same. For example if we have 4 depth values on a pixel: 0, 0, 1, and 1. Then the linearly averaged value will be 0.5, but there was no objects at the depth position.
Since the pixel shader needs to fetch 8 texels, it is very expensive. One way to solve this problem is to differentiate edge pixels from non-edge pixels. On non-edge pixel, we perform one time calculation, while we still do four times calculation on edge pixels.
To practically implement this idea, a cheap edge detection step is required. On Wolfgang's blog, a guy, benualdo, left an interesting idea: http://diaryofagraphicsprogrammer.blogspot.com/2010/03/edge-detection-trick.html
From his idea, I postulated an interesting characteristics of normal values. The length of a normal value is always one by the definition. However, if we linearly interpolate two normal values, the length may decrease. The length will be kept at one only when the normal values are the same. By this characteristics, we can determine whether a pixel includes four same normal values or not by checking the length of the averaged normal value. In other words, by one time of texture fetching with linear filter, we are able to check four normal values; we save three times of texture fetching. I will call this "normal length checking".
The bigger problem was on the depth checking part. I spent about 3 days thinking of depth checking with any similar way to the normal length checking trick. The first way I came up with is to make the 1 dimensional depth value to be 2 dimensional value; ( y = depth, x = 1 - depth ), and normalize it. When the depth values are different, linearly interpolating the normalized value will make the length smaller. This interesting idea didn't work, because we usually use 24 bits for depth and we need 24bits + 24bits to do this. Although I found that 24bits + 16bits is enough to detect edges, I could not accommodate the 2 bytes on any buffers. Normal buffer needs to use 3 channels for the normal and only one channel is left. I tried to encode the normal values onto 2 channels, but I found 2 channels are not enough to do the normal length checking trick. Thus I had to find another way.
My last choice was to use normal direction checking. The way is similar to the toon shading edge detection. When a normal value points to outward from the screen, the pixel is an edge pixel; edge = 0.2 > dot( normal, (0, 0, 1) ). A difference is that on our case false-positive is allowed. In other words, the result will be fine even if we misjudge a non-edge as an edge; we will need little bit more calculations but the result will be the same. On toon shading, this kind of false-positive will make the edge line thicker, which make the result bad.
To prevent too much performance leak, I adopted the Centroid trick that is well explained on ShaderX7. The assumption is that if a pixel is inside of a triangle, it is not an edge pixel, so that we can easily reject those non-edge pixels by checking the centroid value. This reduces a big amount of false-positive edges from the normal direction checking. The centroid information is stored on the alpha channel of the normal buffer.
I like to add some of comments about the centroid trick. The basic idea was very interesting. However, after I implemented it, I soon found that it gave me almost wire-frame-like edges. For example if we have a sphere which consists of several triangles, the centroid trick will indicate those seam parts between triangles as edges. But those pixels are not edges in the sense of normal continuity and depth continuity. In addition, if we use normal map during the normal buffer rendering, pixels in the middle of triangles may need to be considered as edges due to the normal discontinuity. Furthermore, PS3 is based on tiles. The wire-frame-like edges are actually covering almost every screen, although they are sparse. The Stencil cull implementation on PS3 was almost disabled in the situation.
PS3 had another problem with the Centroid trick. PS3 sends the identical value as a centroid value where a pixel is partially covered if the polygon covers the middle of the pixel. It was mentioned on the document and a DevNet supporting guy told me the behavior is hardware-wired so that they have no way to change it. According to my rough calculation only 2/3 of actual edges are detected by the Centroid trick. In other words 1/3 are missed. I couldn't give up this trick, because it makes the edge detection very fast, although the quality may decrease.
 On my implementation, first the normal length checking will return edges. Remain pixels are tested with the centroid trick, and then the normal direction checking takes place. This requires only 1 time of texture fetching and was fast enough to perform in 1.25ms at 720p.
On my implementation, first the normal length checking will return edges. Remain pixels are tested with the centroid trick, and then the normal direction checking takes place. This requires only 1 time of texture fetching and was fast enough to perform in 1.25ms at 720p.The result between the normal direction checking and the depth checking on four texels, which is expensive, was little bit different, but the direction checking was very good enough with respect to the cost.
Mar 22, 2010
Version control system: Mercury
On Joel on blog, I found an interesting article posted: http://www.joelonsoftware.com/items/2010/03/17.html
It is a kind of introductory of Mercury source version control system.
First I thought we have already enough number of source version control systems such as Subversion, CVS, and AlienBrain.
The very first time I have heard about Mercury is from Google code. They actively supported it and they even had a video clip for it. I watched it but I didn't get how different it is from others.
Joel introduced it in a easy way, and I also think it is a very important big progress in software engineering. He also kindly made a tutorial of it: http://hginit.com I will try it on google code at a next personal project.
I will try it on google code at a next personal project.
In a nut shell, Mercury is different from others in the sense that it stores "changes between versions" while previous systems store each version.
*PS: I don't see eclipse plugin for Mercury yet.
It is a kind of introductory of Mercury source version control system.
First I thought we have already enough number of source version control systems such as Subversion, CVS, and AlienBrain.
The very first time I have heard about Mercury is from Google code. They actively supported it and they even had a video clip for it. I watched it but I didn't get how different it is from others.
Joel introduced it in a easy way, and I also think it is a very important big progress in software engineering. He also kindly made a tutorial of it: http://hginit.com
 I will try it on google code at a next personal project.
I will try it on google code at a next personal project.In a nut shell, Mercury is different from others in the sense that it stores "changes between versions" while previous systems store each version.
*PS: I don't see eclipse plugin for Mercury yet.
Mar 16, 2010
GPG8 is published.
Today I was checking Amazon and I found Game Programming Gems 8 is published. This time I expect more than usual, because last year there were big progress in graphics programming such as SSAO, and pre-lighting. And there were several impressive games published.
This time I expect more than usual, because last year there were big progress in graphics programming such as SSAO, and pre-lighting. And there were several impressive games published.
From the table of contents, it contains about SPUs, Code coverage and face rendering... I must read it.
 This time I expect more than usual, because last year there were big progress in graphics programming such as SSAO, and pre-lighting. And there were several impressive games published.
This time I expect more than usual, because last year there were big progress in graphics programming such as SSAO, and pre-lighting. And there were several impressive games published.From the table of contents, it contains about SPUs, Code coverage and face rendering... I must read it.
Mar 15, 2010
GCC converts variables into SSA form
I was gathering some information of GCC with respect to my prior article. And I found that GCC is converting code into SSA form: http://gcc.gnu.org/wiki/SSA. SSA stands for "Single Static Assignment."
It is quite surprising me, because DEF-USE relationship is used for software testing and I haven't thought testing and compiler is related; indeed they must be able to share big amount of parsing technique.
In addition, personally I prefer to use "const" keyword for every single local variables. Some programmer don't like to see const keywords, because it makes source code longer. And they may think it increases the number of local variables and therefore it increases the size of the binary code. If compiler is internally converting to SSA form, then there is no way to reduce the binary code size by not using "const".
Hence I found a better excuse to keep using const keyword for local variables. :-)
It is quite surprising me, because DEF-USE relationship is used for software testing and I haven't thought testing and compiler is related; indeed they must be able to share big amount of parsing technique.
In addition, personally I prefer to use "const" keyword for every single local variables. Some programmer don't like to see const keywords, because it makes source code longer. And they may think it increases the number of local variables and therefore it increases the size of the binary code. If compiler is internally converting to SSA form, then there is no way to reduce the binary code size by not using "const".
Hence I found a better excuse to keep using const keyword for local variables. :-)
Mar 14, 2010
Use Perfect Hash Table for alternative way of switch.
My question I had yesterday is how better "switch" performs comparing to "else if". For example, when we have a piece of code like this:
More intuitive representation for this testing can be like this:
According to an article on CodeGuru, however, "switch" statement will be replaced by "else if". See the article: http://www.codeguru.com/cpp/cpp/cpp_mfc/comments.php/c4007/?thread=48816
A faster and ideal implementation will be like this:
One problem of "jump table" is that the jump table can be too big. When we have a big gap between two values, like "0", and "40000", we still need to have values for 1, 2, 3,... 39999, which will never be used.
The article also mentions the jump table. However, when the table became ridiculously big in some cases, it retreats to "else if".
According to another article, GCC does test "density" of values on "cases". See the article: http://old.nabble.com/Switch-statement-optimization-td5248739.html
The article says when some of values are close enough, GCC will use jump table for those values only, while it still uses "else if" for other sparse values. For example, when we have values like "1", "2", "3", and "40000", GCC will use jump table for those close values "1", "2", and "3", and it will use "else if" for the distant value "40000".
The problem that I am still not happy is that it still uses "else if", although it does use jump table partially.
My idea to improve this problem is to use Perfect Hash Table.
 Hash table is a table that contains both key value and mapped value. For the example above, "1" is mapped to "doSomething1" and "40000" is mapped to "doSomething40000".
Hash table is a table that contains both key value and mapped value. For the example above, "1" is mapped to "doSomething1" and "40000" is mapped to "doSomething40000".
One down side of Hash Table idea is that "hash function" may not as fast as jump table address calculation.
For this down side, it is unavoidable that Hash Function calculation is expensive than direct address calculation by its nature.
However, the cost of Hash function varies depending on what Hash Function we are going to use. So we should be able to control the cost by selecting the hash function.
There are several well-known hash functions. It seems like most of Hash Function Implementations are focusing on String key values, while I need optimal Hash functions for Integer values; for example, gperf and CMPH. An article I found shows Integer Hash Functions: http://www.concentric.net/~Ttwang/tech/inthash.htm
For one case of the article, "32 bit Mix function", it does 11 CPU cycle on HP9000, which is relatively old platform. In addition, those hash function can utilize parallel operations, which can perform faster.
A point is that Hash function for integer is not crazily expensive. Since it doesn't have Branch operation, it should be faster then a bunch of "else if".
Another down side is that hash values may conflict for different key values, then it needs to take additional steps to resolve it.
For this down side, we can use the idea of "Perfect hash table".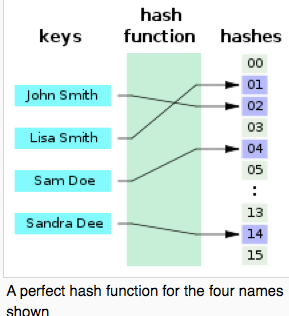 Perfect hash table is a hash table that does not have confliction at all. In a easy way to think of the perfect hash table is an hash table whose reserved size is very big while the number of values in the hash table is small.
Perfect hash table is a hash table that does not have confliction at all. In a easy way to think of the perfect hash table is an hash table whose reserved size is very big while the number of values in the hash table is small.
Therefore we can avoid confliction problem by using Perfect Hash Table. Mose of cases, Perfect Hash Table is not good at inserting and deleting in the middle of process. In other words, we need to know every values that are going to be in the table when we create the perfect hash table. Fortunately C/C++ requires the values on "case" to be constant values. So we know every values at compile time; in other words, compiler knows every values at compile time.
There is another concept, "Minimal Perfect Hash Table".
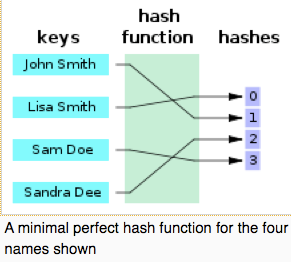 Minimal Perfect Hash Table is a hash table whose reserved size is same with the number of keys on it without any conflict.
Minimal Perfect Hash Table is a hash table whose reserved size is same with the number of keys on it without any conflict.
It sounds very nice, but the hash function for minimal perfect hash function is at least 4 times expensive than normal hash function. One example of Minimal Perfect Hash Function is BDZ algorithm: http://cmph.sourceforge.net/bdz.html
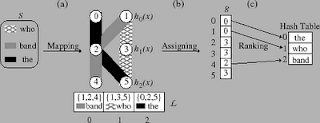 The basic idea of BDZ was surprisingly simple to me. The idea seems very useful for data compression. But it does 3 times of normal hash function to get perfect hash table and it does additional calculation to achieve minimal perfect hash table.
The basic idea of BDZ was surprisingly simple to me. The idea seems very useful for data compression. But it does 3 times of normal hash function to get perfect hash table and it does additional calculation to achieve minimal perfect hash table.
In brief, using Perfect Hash Table saves memory space than jump table and it performs faster than a bunch of "else if". On the other hand, it is slower than jump table and it may (or may not) take more space than "else if" way. Therefore, using Perfect Hash Table for "switch statement" is an alternative way in between "else if" replacement way and "jump table" way. It can certainly perform better for the cases that jump table does not fit. In addition, this evaluation can be done by compiler at compile time, so I believe a better compiler should consider this option for internal optimization.
if( a == 1 ) doSomething1();For each line, CPU, more precisely ALU, will evaluate each statement: "a == 1", "a == 2" and so on. In other words, CPU need to calculate 40000 times for the same value "a".
else if( a == 2 ) doSomething2();
else if( a == 3 ) doSomething3();
....
else if( a == 40000 ) doSomething40000();
More intuitive representation for this testing can be like this:
switch( a )This "switch statement" gives us an illusion that CPU will evaluate the value of "a" only one time.
{
case 1: doSomething1(); break;
case 2: doSomething2(); break;
case 3: doSomething3(); break;
...
case 40000: doSomething4000(); break;
}
According to an article on CodeGuru, however, "switch" statement will be replaced by "else if". See the article: http://www.codeguru.com/cpp/cpp/cpp_mfc/comments.php/c4007/?thread=48816
A faster and ideal implementation will be like this:
typedef void (*CB)();This idea is called "jump table". In this implementation, CPU does not evaluate the "a" value 40000 times but does only once. In other words, this way is faster.
CB doSomethings[] = { doSomething0(), doSomething1(), ... doSomething40000() };
(*(doSomethings[ a ]))();
One problem of "jump table" is that the jump table can be too big. When we have a big gap between two values, like "0", and "40000", we still need to have values for 1, 2, 3,... 39999, which will never be used.
The article also mentions the jump table. However, when the table became ridiculously big in some cases, it retreats to "else if".
According to another article, GCC does test "density" of values on "cases". See the article: http://old.nabble.com/Switch-statement-optimization-td5248739.html
The article says when some of values are close enough, GCC will use jump table for those values only, while it still uses "else if" for other sparse values. For example, when we have values like "1", "2", "3", and "40000", GCC will use jump table for those close values "1", "2", and "3", and it will use "else if" for the distant value "40000".
The problem that I am still not happy is that it still uses "else if", although it does use jump table partially.
My idea to improve this problem is to use Perfect Hash Table.
 Hash table is a table that contains both key value and mapped value. For the example above, "1" is mapped to "doSomething1" and "40000" is mapped to "doSomething40000".
Hash table is a table that contains both key value and mapped value. For the example above, "1" is mapped to "doSomething1" and "40000" is mapped to "doSomething40000".std::map< int, CB > hashTable;One better property of hash table over "jump table" is that the memory space that the hash table requires does not depend on the values but depends on the number of values, which is preferred. Although hash table need little bit more space than the number of values, it is much less than the size of jump table in this case.
hashTable[ 1 ] = doSomething1;
hashTable[ 40000 ] = doSomething40000;
(*(hashTable[ a ]))();
One down side of Hash Table idea is that "hash function" may not as fast as jump table address calculation.
For this down side, it is unavoidable that Hash Function calculation is expensive than direct address calculation by its nature.
However, the cost of Hash function varies depending on what Hash Function we are going to use. So we should be able to control the cost by selecting the hash function.
There are several well-known hash functions. It seems like most of Hash Function Implementations are focusing on String key values, while I need optimal Hash functions for Integer values; for example, gperf and CMPH. An article I found shows Integer Hash Functions: http://www.concentric.net/~Ttwang/tech/inthash.htm
For one case of the article, "32 bit Mix function", it does 11 CPU cycle on HP9000, which is relatively old platform. In addition, those hash function can utilize parallel operations, which can perform faster.
A point is that Hash function for integer is not crazily expensive. Since it doesn't have Branch operation, it should be faster then a bunch of "else if".
Another down side is that hash values may conflict for different key values, then it needs to take additional steps to resolve it.
For this down side, we can use the idea of "Perfect hash table".
 Perfect hash table is a hash table that does not have confliction at all. In a easy way to think of the perfect hash table is an hash table whose reserved size is very big while the number of values in the hash table is small.
Perfect hash table is a hash table that does not have confliction at all. In a easy way to think of the perfect hash table is an hash table whose reserved size is very big while the number of values in the hash table is small.Therefore we can avoid confliction problem by using Perfect Hash Table. Mose of cases, Perfect Hash Table is not good at inserting and deleting in the middle of process. In other words, we need to know every values that are going to be in the table when we create the perfect hash table. Fortunately C/C++ requires the values on "case" to be constant values. So we know every values at compile time; in other words, compiler knows every values at compile time.
There is another concept, "Minimal Perfect Hash Table".
 Minimal Perfect Hash Table is a hash table whose reserved size is same with the number of keys on it without any conflict.
Minimal Perfect Hash Table is a hash table whose reserved size is same with the number of keys on it without any conflict.It sounds very nice, but the hash function for minimal perfect hash function is at least 4 times expensive than normal hash function. One example of Minimal Perfect Hash Function is BDZ algorithm: http://cmph.sourceforge.net/bdz.html
 The basic idea of BDZ was surprisingly simple to me. The idea seems very useful for data compression. But it does 3 times of normal hash function to get perfect hash table and it does additional calculation to achieve minimal perfect hash table.
The basic idea of BDZ was surprisingly simple to me. The idea seems very useful for data compression. But it does 3 times of normal hash function to get perfect hash table and it does additional calculation to achieve minimal perfect hash table.In brief, using Perfect Hash Table saves memory space than jump table and it performs faster than a bunch of "else if". On the other hand, it is slower than jump table and it may (or may not) take more space than "else if" way. Therefore, using Perfect Hash Table for "switch statement" is an alternative way in between "else if" replacement way and "jump table" way. It can certainly perform better for the cases that jump table does not fit. In addition, this evaluation can be done by compiler at compile time, so I believe a better compiler should consider this option for internal optimization.
Mar 4, 2010
Features for next generation game engine.
In my mind, there are several unsatisfied demand for game engines. It is because most of game engines have been improved from long time ago. For example, game bryo, Unreal, Quake, and Half-Life. Those game engines did not have chance to adopt new concepts.
The features that I want to have are listed here:
The features that I want to have are listed here:
- Interface and contract driven design.
- Support for Unit-Testing.
- Pre-lighting as well as deferred shading and forward shading.
- Progressive rendering.
- SPU support on PS3.
- XNA support through C++ DLL.
- No preprocessor codes such as #ifdef.
Truck number or lucky number.
Truck number is the minimum number of people who can mess up a project. The higher, the better.
For example, the truck number is 1 for a project, meaning that when one person got hit by a truck then the project cannot go on anymore.
If the example is too cruel, then we can also call it lucky number. For example, a person get big money by a lottery, he quit the company and the project cannot go on anymore. It means the lucky number is one. Now our company has one HR person. He is out of country more than 30 days. I need to talk to him about my Visa but I cannot process it; I'm wondering he might actually get a lottery.
Now our company has one HR person. He is out of country more than 30 days. I need to talk to him about my Visa but I cannot process it; I'm wondering he might actually get a lottery.
One may think higher lucky number means less efficient, because of too much redundancy. Well, it may be true. Insurance is for reducing risk not to increase efficiency. And the risk may mess up your company or your life.
My company is small as a matter of fact. But I do not think it is as small as it can afford only one HR person. I do believe it is rather a matter of experience. People who don't have various experiences tend not to prepare for other risky situations.
For example, the truck number is 1 for a project, meaning that when one person got hit by a truck then the project cannot go on anymore.
If the example is too cruel, then we can also call it lucky number. For example, a person get big money by a lottery, he quit the company and the project cannot go on anymore. It means the lucky number is one.
 Now our company has one HR person. He is out of country more than 30 days. I need to talk to him about my Visa but I cannot process it; I'm wondering he might actually get a lottery.
Now our company has one HR person. He is out of country more than 30 days. I need to talk to him about my Visa but I cannot process it; I'm wondering he might actually get a lottery.One may think higher lucky number means less efficient, because of too much redundancy. Well, it may be true. Insurance is for reducing risk not to increase efficiency. And the risk may mess up your company or your life.
My company is small as a matter of fact. But I do not think it is as small as it can afford only one HR person. I do believe it is rather a matter of experience. People who don't have various experiences tend not to prepare for other risky situations.
Mar 2, 2010
An idea to enhance SSAO.
AO here means Ambient Occlusion. As well known, AO increases realism in a scene. Some of concave shaped corner of objects are exposed to out side less then convex corners. The concave part will look darker than convex part. AO calculates how much a point is occluded by other geometries.
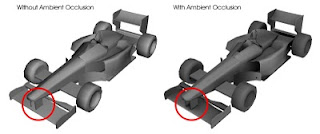 One problem of AO is that it is expansive to calculate. We cannot afford to calculate AO at run-time. So people pre-calculate AO values and they are used at run-time. In this way, AO values are valid only for static objects, because if objects move AO values must be re-calculated and we cannot afford it.
One problem of AO is that it is expansive to calculate. We cannot afford to calculate AO at run-time. So people pre-calculate AO values and they are used at run-time. In this way, AO values are valid only for static objects, because if objects move AO values must be re-calculated and we cannot afford it.
One novel approach was known as SSAO. AO calculation is done in screen-space with depth buffer; optionally with normal buffer.
SSAO does not give as good looking as pre-calculated AO values although it is still better than not using at all. In addition, one thing we need to notice is that SSAO is still not cheap at run-time.
 For the screen-shot above, you can see a sofa on right side which has two cushions. And you can see a table. The screen-shot shows AO between the sofa and table which is represented by darker color. But actually the distance between table and sofa is relatively far, although it appears to be closer on the screen space. So the SSAO result is not quite correct. I feel it is more like dark glow effect from sofa or some kind of wrong shadow.
For the screen-shot above, you can see a sofa on right side which has two cushions. And you can see a table. The screen-shot shows AO between the sofa and table which is represented by darker color. But actually the distance between table and sofa is relatively far, although it appears to be closer on the screen space. So the SSAO result is not quite correct. I feel it is more like dark glow effect from sofa or some kind of wrong shadow.
My idea is a kind of hybrid way between SSAO and pre-calculated AO. When a object is moving, we use SSAO, and when the object stop moving, we use a better AO value that is calculated at run-time. Although AO calculation is expensive then SSAO, once the AO values are calculated, it does not need to be recalculated until the object moves again.
First, we can detect whether or not a object is stabilized from physic engine API. Once stabilizing objects or sleeping objects were a big issue on physic implementations. People have improved it year by year. Since physic engines are handling this big issue, we can easily find which objects are about to be static.
Second, we can use SSAO until the better AO values are calculated. It is ok to spend more time than two or several frames as long as SSAO plays its role. Once the AO calculation is done, we replace SSAO with the better AO values. Then we will get a better look and don't need to do the expensive SSAO for the static objects.
 This is just an idea. I haven't tested it yet.
This is just an idea. I haven't tested it yet.
One thing I'm afraid of is that when we replace SSAO with the better AO, player may notice the changes. It may give wrong information that something was moving there. So it should be gradually changing. Another thing is that I don't know how much expensive the better AO calculation will be. It may not feasible at run-time at all. Lastly, I am not quite sure how to differentiate SSAO rendering and AO rendering in a scene. Since SSAO will use just a big screen-quad, we may or may not be able to selectively calculate SSAO with a stencil buffer.
I wish I can have a chance to implement this idea sooner or later.
 One problem of AO is that it is expansive to calculate. We cannot afford to calculate AO at run-time. So people pre-calculate AO values and they are used at run-time. In this way, AO values are valid only for static objects, because if objects move AO values must be re-calculated and we cannot afford it.
One problem of AO is that it is expansive to calculate. We cannot afford to calculate AO at run-time. So people pre-calculate AO values and they are used at run-time. In this way, AO values are valid only for static objects, because if objects move AO values must be re-calculated and we cannot afford it.One novel approach was known as SSAO. AO calculation is done in screen-space with depth buffer; optionally with normal buffer.
SSAO does not give as good looking as pre-calculated AO values although it is still better than not using at all. In addition, one thing we need to notice is that SSAO is still not cheap at run-time.
 For the screen-shot above, you can see a sofa on right side which has two cushions. And you can see a table. The screen-shot shows AO between the sofa and table which is represented by darker color. But actually the distance between table and sofa is relatively far, although it appears to be closer on the screen space. So the SSAO result is not quite correct. I feel it is more like dark glow effect from sofa or some kind of wrong shadow.
For the screen-shot above, you can see a sofa on right side which has two cushions. And you can see a table. The screen-shot shows AO between the sofa and table which is represented by darker color. But actually the distance between table and sofa is relatively far, although it appears to be closer on the screen space. So the SSAO result is not quite correct. I feel it is more like dark glow effect from sofa or some kind of wrong shadow.My idea is a kind of hybrid way between SSAO and pre-calculated AO. When a object is moving, we use SSAO, and when the object stop moving, we use a better AO value that is calculated at run-time. Although AO calculation is expensive then SSAO, once the AO values are calculated, it does not need to be recalculated until the object moves again.
First, we can detect whether or not a object is stabilized from physic engine API. Once stabilizing objects or sleeping objects were a big issue on physic implementations. People have improved it year by year. Since physic engines are handling this big issue, we can easily find which objects are about to be static.
Second, we can use SSAO until the better AO values are calculated. It is ok to spend more time than two or several frames as long as SSAO plays its role. Once the AO calculation is done, we replace SSAO with the better AO values. Then we will get a better look and don't need to do the expensive SSAO for the static objects.
 This is just an idea. I haven't tested it yet.
This is just an idea. I haven't tested it yet.One thing I'm afraid of is that when we replace SSAO with the better AO, player may notice the changes. It may give wrong information that something was moving there. So it should be gradually changing. Another thing is that I don't know how much expensive the better AO calculation will be. It may not feasible at run-time at all. Lastly, I am not quite sure how to differentiate SSAO rendering and AO rendering in a scene. Since SSAO will use just a big screen-quad, we may or may not be able to selectively calculate SSAO with a stencil buffer.
I wish I can have a chance to implement this idea sooner or later.
Mar 1, 2010
Sony leap year problem.
Today is March 1st, but PlayStation3 hardware recognized it as Feb 29th, because its internal clock had a problem.
Because of this reason, game players of play station 3 could not log-in the server; in fact, I'm not quite understanding why and how. In addition, I also could not work on PS3 this morning, because our game needed to log-in, due to Trophy system.
 I was thinking that Microsoft people who developed X-Box must be laughing; indeed X-Box was fine today.
I was thinking that Microsoft people who developed X-Box must be laughing; indeed X-Box was fine today.
Game related programmers must learn how important Unit-Testing is...; I have never seen any game engine that support unit testing yet.
Because of this reason, game players of play station 3 could not log-in the server; in fact, I'm not quite understanding why and how. In addition, I also could not work on PS3 this morning, because our game needed to log-in, due to Trophy system.
 I was thinking that Microsoft people who developed X-Box must be laughing; indeed X-Box was fine today.
I was thinking that Microsoft people who developed X-Box must be laughing; indeed X-Box was fine today.Game related programmers must learn how important Unit-Testing is...; I have never seen any game engine that support unit testing yet.
Subscribe to:
Posts (Atom)
