My question I had yesterday is how better "switch" performs comparing to "else if". For example, when we have a piece of code like this:
if( a == 1 ) doSomething1();
else if( a == 2 ) doSomething2();
else if( a == 3 ) doSomething3();
....
else if( a == 40000 ) doSomething40000();
For each line, CPU, more precisely ALU, will evaluate each statement: "a == 1", "a == 2" and so on. In other words, CPU need to calculate 40000 times for the same value "a".
More intuitive representation for this testing can be like this:
switch( a )
{
case 1: doSomething1(); break;
case 2: doSomething2(); break;
case 3: doSomething3(); break;
...
case 40000: doSomething4000(); break;
}
This "switch statement" gives us an illusion that CPU will evaluate the value of "a" only one time.
According to an article on CodeGuru, however, "switch" statement will be replaced by "else if". See the article: http://www.codeguru.com/cpp/cpp/cpp_mfc/comments.php/c4007/?thread=48816
A faster and ideal implementation will be like this:
typedef void (*CB)();
CB doSomethings[] = { doSomething0(), doSomething1(), ... doSomething40000() };
(*(doSomethings[ a ]))();
This idea is called "jump table". In this implementation, CPU does not evaluate the "a" value 40000 times but does only once. In other words, this way is faster.
One problem of "jump table" is that the jump table can be too big. When we have a big gap between two values, like "0", and "40000", we still need to have values for 1, 2, 3,... 39999, which will never be used.
The article also mentions the jump table. However, when the table became ridiculously big in some cases, it retreats to "else if".
According to another article, GCC does test "density" of values on "cases". See the article: http://old.nabble.com/Switch-statement-optimization-td5248739.html
The article says when some of values are close enough, GCC will use jump table for those values only, while it still uses "else if" for other sparse values. For example, when we have values like "1", "2", "3", and "40000", GCC will use jump table for those close values "1", "2", and "3", and it will use "else if" for the distant value "40000".
The problem that I am still not happy is that it still uses "else if", although it does use jump table partially.
My idea to improve this problem is to use Perfect Hash Table.

Hash table is a table that contains both key value and mapped value. For the example above, "1" is mapped to "doSomething1" and "40000" is mapped to "doSomething40000".
std::map< int, CB > hashTable;
hashTable[ 1 ] = doSomething1;
hashTable[ 40000 ] = doSomething40000;
(*(hashTable[ a ]))();
One better property of hash table over "jump table" is that the memory space that the hash table requires does not depend on the values but depends on the number of values, which is preferred. Although hash table need little bit more space than the number of values, it is much less than the size of jump table in this case.
One down side of Hash Table idea is that "hash function" may not as fast as jump table address calculation.
For this down side, it is unavoidable that Hash Function calculation is expensive than direct address calculation by its nature.
However, the cost of Hash function varies depending on what Hash Function we are going to use. So we should be able to control the cost by selecting the hash function.
There are several well-known hash functions. It seems like most of Hash Function Implementations are focusing on String key values, while I need optimal Hash functions for Integer values; for example, gperf and CMPH. An article I found shows Integer Hash Functions: http://www.concentric.net/~Ttwang/tech/inthash.htm
For one case of the article, "32 bit Mix function", it does 11 CPU cycle on HP9000, which is relatively old platform. In addition, those hash function can utilize parallel operations, which can perform faster.
A point is that Hash function for integer is not crazily expensive. Since it doesn't have Branch operation, it should be faster then a bunch of "else if".
Another down side is that hash values may conflict for different key values, then it needs to take additional steps to resolve it.
For this down side, we can use the idea of "Perfect hash table".
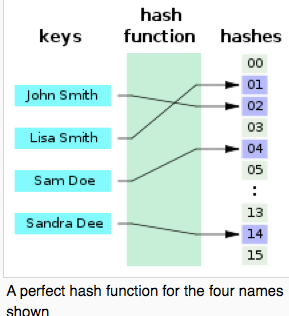
Perfect hash table is a hash table that does not have confliction at all. In a easy way to think of the perfect hash table is an hash table whose reserved size is very big while the number of values in the hash table is small.
Therefore we can avoid confliction problem by using Perfect Hash Table. Mose of cases, Perfect Hash Table is not good at inserting and deleting in the middle of process. In other words, we need to know every values that are going to be in the table when we create the perfect hash table. Fortunately C/C++ requires the values on "case" to be constant values. So we know every values at compile time; in other words, compiler knows every values at compile time.
There is another concept, "Minimal Perfect Hash Table".
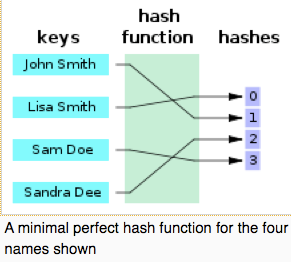
Minimal Perfect Hash Table is a hash table whose reserved size is same with the number of keys on it without any conflict.
It sounds very nice, but the hash function for minimal perfect hash function is at least 4 times expensive than normal hash function. One example of Minimal Perfect Hash Function is BDZ algorithm: http://cmph.sourceforge.net/bdz.html
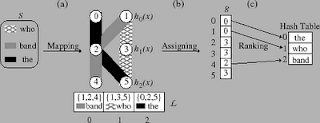
The basic idea of BDZ was surprisingly simple to me. The idea seems very useful for data compression. But it does 3 times of normal hash function to get perfect hash table and it does additional calculation to achieve minimal perfect hash table.
In brief, using Perfect Hash Table saves memory space than jump table and it performs faster than a bunch of "else if". On the other hand, it is slower than jump table and it may (or may not) take more space than "else if" way. Therefore, using Perfect Hash Table for "switch statement" is an alternative way in between "else if" replacement way and "jump table" way. It can certainly perform better for the cases that jump table does not fit. In addition, this evaluation can be done by compiler at compile time, so I believe a better compiler should consider this option for internal optimization.
 Although MS says it was open 'by design', who knows how long it will last; even MS wouldn't know.
Although MS says it was open 'by design', who knows how long it will last; even MS wouldn't know.














































